
-
Tips

What is Visual Search Guide: Benefits and Optimization Tips
Innovations in the field of search by image have changed the game of content creation in all fields of life.…
Read More » -
PHP Scripts
Booster Traffic Exchange System – traffic exchange system Free Download
This is a traffic exchange system that allows users to earn points by automatically visiting other sites, and users can…
Read More » -
PHP Scripts
Mass Site Visitor – A Traffic Bot For Windows 1.1 Free Download
Mass Site Visitor (MSV) is designed to generate large amounts of traffic to websites of your choice through the list of proxies in…
Read More » -
PHP Scripts
Support Centre – Advanced PHP Ticket System Free Download
Support Centre – Advanced PHP Ticket System is a powerful PHP script that allows users to create tickets and get…
Read More » -
PHP Scripts

GetVideo – NodeJS Youtube Video Downloader Free Download
GetVideo created with the latest technologies such as NodeJs, Bootstrap 4, Jquery, and others. You can download 1080p ( Video only…
Read More » -
Themes

Reobiz – Consulting Business WordPress Theme Free Download
Reobiz – Consulting Business WordPress Theme Reobiz is a modern and unique Consulting Business WordPress Theme. It comes with high-quality…
Read More » -
Themes
Real Estate 7 – Real Estate WordPress Theme Free Download
Real Estate 7 – Real Estate WordPress Theme THE LAST REAL ESTATE WORDPRESS THEME YOU’LL EVER NEED TO BUY! If…
Read More » -
Themes

Trydo – Creative Agency & Portfolio Free Download
Trydo – Creative Agency & Portfolio WordPress Theme This is Trydo creative modern agency & portfolio theme that can run…
Read More » -
Themes

Kable – Multipurpose WooCommerce Theme Free Download
Kable – Multipurpose WooCommerce Theme Kable – is a clean, Modern & minimal professional WooCommerce WordPress theme for shopping online…
Read More » -
Themes

Blacksilver | Photography Theme for WordPress Free Download
Blacksilver | Photography Theme for WordPress Welcome to Blacksilver Photography theme for WordPress. Blacksilver photography WordPress theme is designed with…
Read More » -
Themes

Verve – High-Style WordPress Theme Free Download
Verve – High-Style WordPress Theme [Latest Version] Main Features Carousel Navigation Multiple menu bar display options Completely flexible footer. Turn-ON/OFF,…
Read More » -
Themes
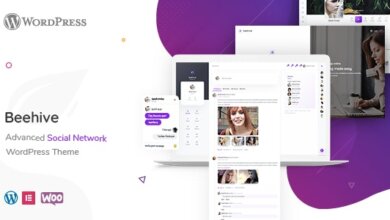
Beehive – Social Network WordPress Theme Free Download
Beehive – Social Network WordPress Theme Beehive is an advanced social network BuddyPress theme which comes with advanced social features,…
Read More »